| Version 20 (modified by , 16 years ago) (diff) |
|---|
MCF Compute Manager
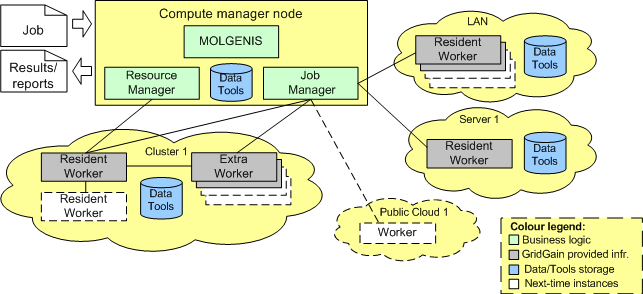
Our computational infrastructure is organised as a ”cloud” and implemented using the GridGain 2.1.1 development platform. The whole computational logic is located at one cloud node, which is the MCF Compute Manager node. The rest of the computational base is a standard gridgain software deployed in a local network, cluster or server. MOLGENIS data management modules are also deployed on the MCF Compute Manager node. The topology of our ”cloud” is shown below

MCF Compute Manager consists of two modules:
- Job Manager, which distributes jobs across cloud Worker nodes and monitors their executions, and
- Resource Manager, which starts and stops Worker nodes on the cluster.
The Job Manager logic is rather straightforward and can be easily adjusted for use on a specific cluster or server. After a job is received by Job Manager, it is registered in the database and passed to the Worker nodes for execution. There are two different kinds of Worker nodes in the system. These are Resident Workers and Extra Workers. Basically, these nodes are the same standard gridgain nodes and differ only by name or a cloud segment. Why do we need two different kinds of nodes in the system, if these nodes have the same functionallity? A workflow operation is an execution of a bioinformatics analysis tool, which is invoked from a command line. A usual output is files and a standard command-line output or/and error. The difference between two kinds of Worker nodes is in a way analysis tools are invoked from them. Resident Worker starts a job by sumbitting a shell script to the cluster job scheduler. In contrast to Resident Worker, Extra Worker directly invokes an analysis tool. In this way, the cluster scheduler can be circumvented.
Extra Workers are pre-started and stopped by Resident Worker. Resident Worker receives a command from Resource Manager and starts Extra Workers by submitting a script to the cluster scheduler to start them. After being started, Extra Workers communicate to Job Manager and register themselves. In practice, it can take more time to pre-start many Extra Workers for direct parallel execution of analysis operations than submit scripts to a cluster scheduler to execute the same operations. Furthermore, running many Extra Workers in the system increases the network load on the Job Manager node. Still, Extra Workers can be efficiently used in the system having an advanced strategy to pre-start them, that is planned to be developed in the future.
Resource Manager is required only if a computational cluster is used in the system. Its logic is also straightforward and directly depends on the policies of the cluster used. We tested our framework on the Millipede HPC cluster , which appears in the TOP500 supercomputers list. This cluster has a policy that any cluster job execution should not exceed the ten days limit to assure availability of cluster resources to all users. This means, that Resident Worker cannot run longer that ten days either. In our current implementation to keep a cluster as a part of our computational cloud, Resident Worker starts a new Resident Worker node in some time before it will be removed by the cluster administrator, e.g. two days before the end of a ten-days period. A request for starting a new Resident Worker is passed to the cluster scheduler and processed in some time depending on a cluster load. Hence, we assure that at least one Resident Worker is running on the cluster.
MCF Compute Manager code base and examples can be found here.
Attachments (1)
- back-end.gif (25.9 KB) - added by 16 years ago.
{kind=link}
Download all attachments as: .zip